How to Upload M4a File to S3
EXPEDIA Group TECHNOLOGY — SOFTWARE
How to Upload Large Files to AWS S3
Using Amazon'southward CLI to reliably upload up to v terabytes
In a single operation, you can upload upwardly to 5GB into an AWS S3 object. The size of an object in S3 can be from a minimum of 0 bytes to a maximum of 5 terabytes, and then, if you are looking to upload an object larger than v gigabytes, you need to utilise either multipart upload or split the file into logical chunks of upward to 5GB and upload them manually as regular uploads. I will explore both options.
Multipart upload
Performing a multipart upload requires a procedure of splitting the file into smaller files, uploading them using the CLI, and verifying them. The file manipulations are demonstrated on a UNIX-like system.
- Earlier you upload a file using the multipart upload process, we need to calculate its base64 MD5 checksum value:
$ openssl md5 -binary test.csv.gz| base64 a3VKS0RazAmJUCO8ST90pQ==
2. Split up the file into small files using the carve up command:
Syntax
split [-b byte _ count[one thousand|m]] [-l line _ count] [file [name]] Option -b Create smaller files byte_count bytes in length.
`k' = kilobyte pieces
`thousand' = megabyte pieces. -50 Create smaller files line _ count lines in length.
Splitting the file into 4GB blocks:
$ split -b 4096m test.csv.gz examination.csv.gz.part- $ ls -50 exam*
-rw-r--r--@ one user1 staff 7827069512 Aug 26 16:20 test.csv.gz
-rw-r--r-- ane user1 staff 4294967296 Aug 26 sixteen:36 test.csv.gz.part-aa
-rw-r--r-- one user1 staff 3532102216 Aug 26 xvi:36 test.csv.gz.role-ab
iii. Now, multipart upload should be initiated using the create-multipart-upload command. If the checksum that Amazon S3 calculates during the upload doesn't friction match the value that you lot entered, Amazon S3 won't store the object. Instead, you receive an error message in response. This step generates an upload ID, which is used to upload each part of the file in the next steps:
$ aws s3api create-multipart-upload \
--saucepan bucket1 \
--primal temp/user1/test.csv.gz \
--metadata md5=a3VKS0RazAmJUCO8ST90pQ== \
--profile dev {
"AbortDate": "2020-09-03T00:00:00+00:00",
"AbortRuleId": "deleteAfter7Days",
"Bucket": "bucket1",
"Key": "temp/user1/exam.csv.gz",
"UploadId": "qk9UO8...HXc4ce.Vb"
}
Explanation of the options:
--bucket bucket name
--key object name (can include the path of the object if you want to upload to any specific path)
--metadata Base64 MD5 value generated in step 1
--profile CLI credentials profile name, if you have multiple profiles
4. Next upload the first smaller file from step 1 using theupload-part command. This step will generate an ETag, which is used in afterward steps:
$ aws s3api upload-part \
--bucket bucket1 \
--key temp/user1/test.csv.gz \
--part-number one \
--trunk test.csv.gz.part-aa \
--upload-id qk9UO8...HXc4ce.Vb \
--profile dev {
"ETag": "\"55acfb877ace294f978c5182cfe357a7\""
}
In which:
--function-number file part number
--body file proper noun of the part being uploaded
--upload-id upload ID generated in step 3
five. Upload the 2d and concluding part using the same upload-office command with --office-number 2 and the 2d function's filename:
$ aws s3api upload-part \
--bucket bucket1 \
--fundamental temp/user1/examination.csv.gz \
--office-number two \
--body exam.csv.gz.function-ab \
--upload-id qk9UO8...HXc4ce.Vb \
--profile dev {
"ETag": "\"931ec3e8903cb7d43f97f175cf75b53f\""
}
6. To make certain all the parts have been uploaded successfully, y'all tin use the list-parts command, which lists all the parts that have been uploaded so far:
$ aws s3api list-parts \
--bucket bucket1 \
--key temp/user1/exam.csv.gz \
--upload-id qk9UO8...HXc4ce.Vb \
--profile dev {
"Parts": [
{
"PartNumber": 1,
"LastModified": "2020-08-26T22:02:06+00:00",
"ETag": "\"55acfb877ace294f978c5182cfe357a7\"",
"Size": 4294967296
},
{
"PartNumber": 2,
"LastModified": "2020-08-26T22:23:13+00:00",
"ETag": "\"931ec3e8903cb7d43f97f175cf75b53f\"",
"Size": 3532102216
}
], "Initiator": {
"ID": "arn:aws:sts::575835809734:causeless-role/dev/user1",
"DisplayName": "dev/user1"
}, "Possessor": {
"DisplayName": "aws-account-00183",
"ID": "6fe75e...e04936"
}, "StorageClass": "STANDARD"
}
vii. Next, create a JSON file containing the ETags of all the parts:
$ cat partfiles.json
{
"Parts" : [
{
"PartNumber" : 1,
"ETag" : "55acfb877ace294f978c5182cfe357a7"
},
{
"PartNumber" : ii,
"ETag" : "931ec3e8903cb7d43f97f175cf75b53f"
}
]
} eight. Finally, finish the upload process using the complete-multipart-upload command equally beneath:
$ aws s3api consummate-multipart-upload \
--multipart-upload file://partfiles.json \
--bucket bucket1 \
--key temp/user1/test.csv.gz \
--upload-id qk9UO8...HXc4ce.Vb --contour dev {
"Expiration": "expiry-date=\"Fri, 27 Aug 2021 00:00:00 GMT\", rule-id=\"deleteafter365days\"",
"VersionId": "TsD.L4ywE3OXRoGUFBenX7YgmuR54tY5",
"Location":
"https://bucket1.s3.u.s.a.-e-1.amazonaws.com/temp%2Fuser1%2Ftest.csv.gz",
"Bucket": "bucket1",
"Cardinal": "temp/user1/test.csv.gz",
"ETag": "\"af58d6683d424931c3fd1e3b6c13f99e-ii\""
}
9. Now our file object is uploaded into S3.
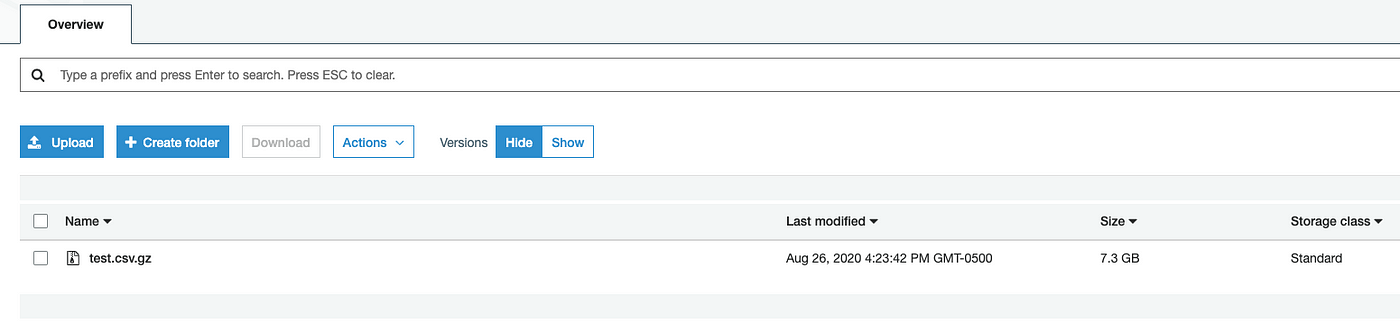
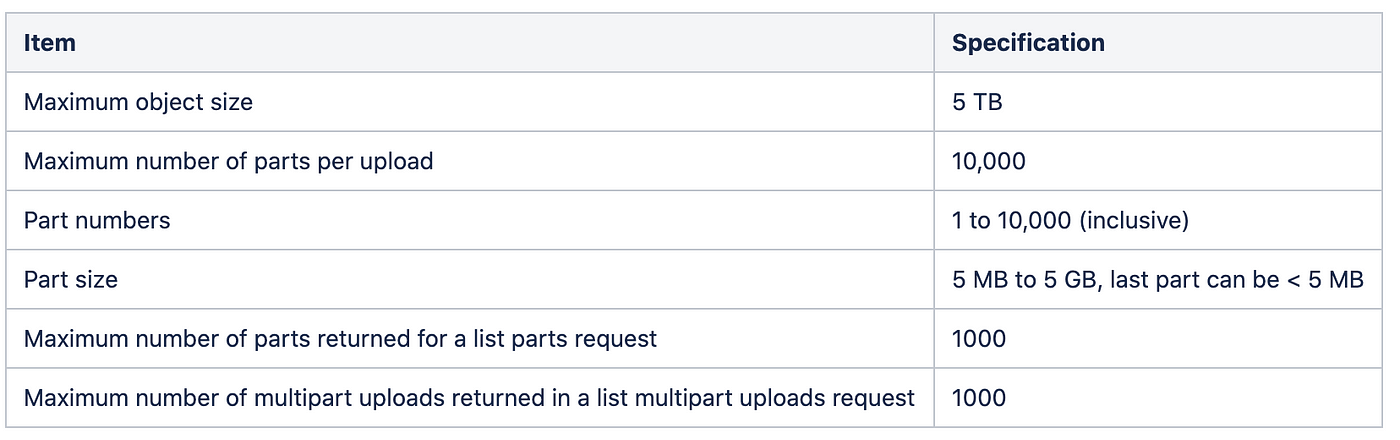
The following tabular array provides multipart upload core specifications. For more than information, see Multipart upload overview.
Finally, Multipart upload is a useful utility to make the file 1 object in S3 instead of uploading it every bit multiple objects (each less than 5GB).

Split up and upload
The multipart upload procedure requires y'all to take special permissions, which is sometimes time-consuming to obtain in many organizations. You can split the file manually and do a regular upload of each part every bit well.
Here are the steps:
- Unzip the file if information technology is a nothing file.
- Split the file based on the number of lines in each file. If it is a CSV file, you can use
parallel --headerto copy the header to each carve up file. I am splitting here after every 2M records:
$ cat test.csv \
| parallel --header : --pipe -N2000000 'cat >file_{#}.csv' iii. zip the file dorsum using gzip <filename> command and upload each file manually every bit a regular upload.
http://lifeatexpediagroup.com
Source: https://medium.com/expedia-group-tech/how-to-upload-large-files-to-aws-s3-200549da5ec1
0 Response to "How to Upload M4a File to S3"
Post a Comment